Solr und Nutch um eigene Felder erweitern
Meine ersten Erfahrungen mit Nutch/Solr als Findemaschine hatte ich ja hier beschrieben. Man kann jetzt etwas eingeben und bekommt auch die richtigen Treffer.
Bisher jedoch ohne die Möglichkeit auch in bestimmten und definierten Felder zu suchen. So möchten man z.B. auf einem Blog auch alle mit einem bestimmten Tag versehenden Dokumente finden in dem man nur in den Tag Felder sucht.
Diese Tags oder andere Schlüsselwörter wie Autor sind im HTML als Metatags hinterlegt.
Damit der Index Solr damit etwas anfangen kann müssen wir zuerst dem Crawler Nutch sagen wo genau diese sind. Diese Beschreibung basiert bis auf einen kleinen Fehler auf dieser Erklärung.
Einstellungen für den Crawler in der Datei conf/nutch-site.xml
1. Wir brauchen die richtig Plugins
<property> <name>plugin.includes</name> <value>protocol-http|urlfilter-regex|parse-(html|tika|metatags)|index-(basic|anchor|metadata)|indexer-solr|scoring-opic|urlnormalizer-(pass|regex|basic)</value> </property>
(Wichtig: auch indexer-solr mit aufnehmen)
2. Welche Meta Tags wollen wir: (Ich nehme einfach mal alle)
<property> <name>metatags.names</name> <value>*</value> </property>
3. Welche Meta Tags wollen wir in indexierete Felder überführen
<property> <name>index.parse.md</name> <value>metatag.description,metatag.keywords</value> </property>
Einstellungen des Indexer Solr in der Datei vi conf/schema.xml
1. Welche Metatags interessieren uns?
<fields> .... <!-- fields for the metatags plugin --> <field name="metatag.description" type="string" stored="true" indexed="true"/> <field name="metatag.keywords" type="string" stored="true" indexed="true"/> ..... <fields>
Ich bin mir nicht sicher ob es wirklich notwendig ist, aber ich habe mir angewöhnt bei meinen Tests immer das Verzeichnis "Crawl" von Nutch und den kompletten Index von Solr zu löschen und dann einen kompletten Reimport zu starten.
Das Löschen des Solr Index kann man über die Befehlszeile mithilfe von:
curl http://solrserver:8983/solr/hagen-bauer-de/update --data '<delete><query>*:*</query></delete>' -H 'Content-type:text/xml; charset=utf-8' curl http://solrserver:8983/solr/hagen-bauer-de/update --data '<commit/>' -H 'Content-type:text/xml; charset=utf-8'
oder über einen Bookmark im Browser erreichen.
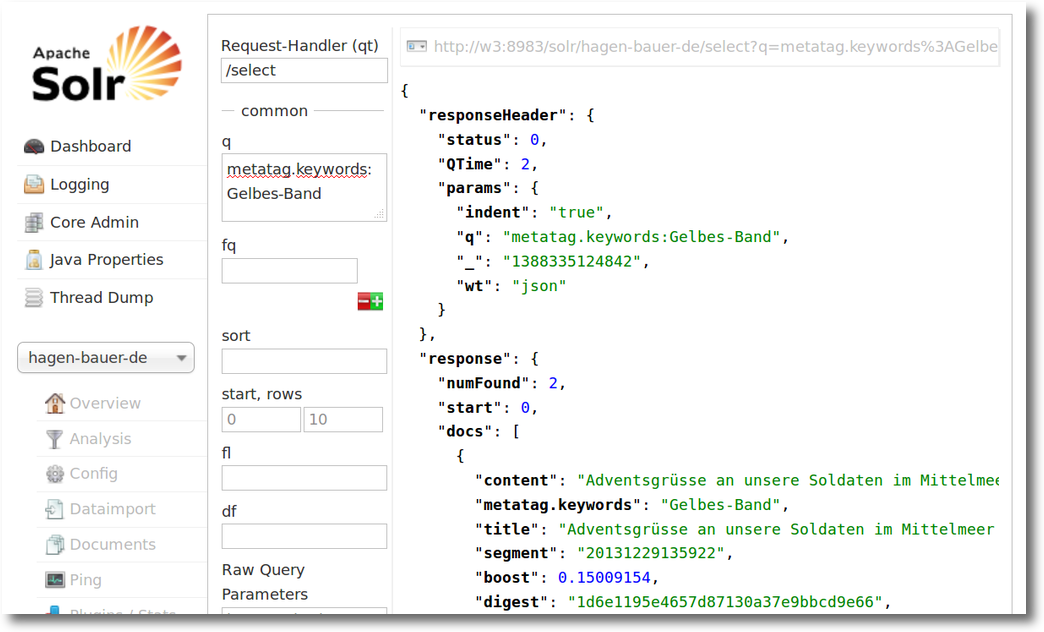
Wenn alles klappt kann man das schnell in der Solr Administratation sehen. In diesem Beispiel habe ich nach einem bestimmten Metatag gesucht und bekomme den Inhalt zu einem der Dokumente angezeigt.